AI Urban Visualizer
This project delivers an AI-powered visualization tool that converts architectural massing models into high-fidelity renderings within seconds. Using Stable Diffusion and ControlNet, the system extracts structural edges and depth from user sketches to generate photorealistic bird’s-eye imagery without manual post-processing. Built for planners, architects, and designers, the tool accelerates early-stage visualization with adjustable parameters, real-time previews, and one-click export—compressing hours of rendering work into a fast, consistent, and intuitive workflow.
Client
A municipal government agency
Duration
1 Month | 2024
System Development
Tools & Stack
React, Tailwind
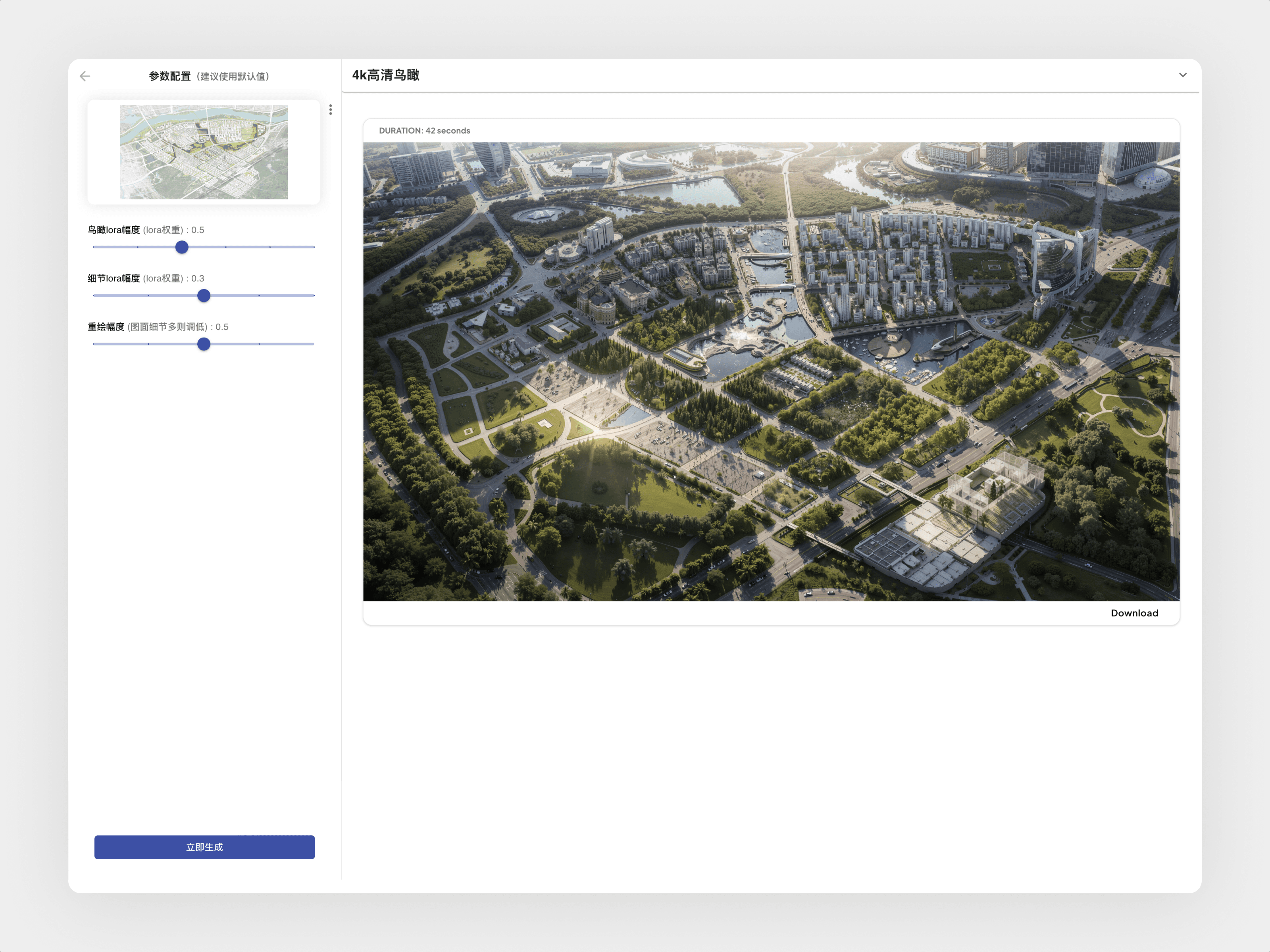
Generation Principle — Edge & Depth-Driven AI Rendering
The tool extracts structural edges and depth maps from user-uploaded sketches, forming a precise geometric foundation for image generation. Using Stable Diffusion with ControlNet, these extracted signals guide the model to preserve massing accuracy while enhancing materials, lighting, and environmental detail. This dual-channel control ensures the final render maintains architectural fidelity while achieving photorealistic visual quality—without manual modeling or post-processing.

Generated Output
Guided by both the structural contour map and depth map, the model reconstructs the scene with accurate geometry and spatial hierarchy. Contours ensure precise building edges and layout, while depth preserves perspective and scale. Together, they enable the system to generate a photorealistic rendering that enriches materials, lighting, and environmental detail—all while remaining true to the original massing model.

Cross-Domain Generation Testing
Even when using a non-architectural image—such as a lotus photo—the platform applies the same contour-and-depth generation principle. By extracting edge structures and spatial hierarchy from the source image, the system reconstructs a photorealistic water-city scene that mirrors the original composition. This illustrates the model’s robustness and its ability to reinterpret diverse inputs into coherent, high-fidelity visual outputs.
